Die Überschrift ist sicher etwas zugespitzt, aber in ihrer Stellungnahme zur „Replizierbarkeit von Forschungsergebnissen“ (Pressemitteilung, PDF) schreibt die DFG: „Neben individuellem Fehlverhalten gibt es für das Qualitätsproblem von Forschung allerdings auch strukturelle Gründe. Das mittlerweile in der Wissenschaft erreichte Gewicht von quantitativ parametrisierenden Steuerungs-, Bewertungs- und Gratifikationssystemen wirkt sich auf die Forschung als gestiegener (und weiter steigender) Wettbewerbs- und Beschleunigungsdruck aus. Dieser manifestiert sich in Entscheidungen (und zugrunde liegenden Entscheidungskriterien) über Karriereschritte, finanzielle Förderung, Publikationsorte oder institutionelle Strukturentwicklungen. Die notwendige skrupulöse Sorgfalt bei der Vorbereitung, Durchführung, Auswertung, Darstellung und Publikation experimenteller und empirisch-quantitativer Forschung braucht Zeit, Gelegenheit, Mittel und Personal. Sie muss eher gegen diesen Wettbewerbs- und Beschleunigungsdruck durchgesetzt werden, als dass sie von ihm befördert würde.“ (Hervorhebung durch K.W.)
Auch wenn es bestimmt einige Zeit dauert, bis sich diese Erkenntnis in der Förderpraxis der DFG auch durchsetzt, ist die Einsicht an sich durchaus bemerkenswert. Es galt doch lang Zeit eher die Überzeugung, dass Kennzahlensysteme dabei helfen, die Qualität in der Wissenschaft zu verbessern.
Die Geschäftsstelle des Rates für Informationsinfrastrukturen (RfII) erstellt wöchentlich einen Newsletter mit Nachrichten aus dem akademischen und wissenschaftspolitischen Umfeld des RfII.
Der RfII Info Ticker bietet einen schnellen und informellen Überblick rund um Entwicklungen in der Wissenschaft unter dem Einfluss des digitalen Wandels. Ausgewertet werden Meldungen zu Informationsinfrastrukturen und Forschungsdaten, Bildung und Hochschulen, wissenschafts- und förderpolitisch relevanten Entwicklungen, Veränderungen im Bereich von Bibliotheken und Publikationssystem sowie rechtlichen, technischen, wirtschaftlichen und wissenschaftlichen Entwicklungen durch die digitale Transformation. Hinweise auf aktuelle Veranstaltungen aus diesem Themenspektrum ergänzen das Informationsangebot.
Die quantitative Survey‐Forschung zielt auf eine möglichst beobachterunabhängige Beschreibung sozialer Phänomene ab. Gegenüber der qualitativen Sozialforschung beansprucht sie den Vorzug einer durch große Zufallsstichproben und Standardisierung gegebenen Verallgemeinerbarkeit sowie Vergleichbarkeit von Ergebnissen aus verschiedenen Kontexten. Im Unterschied zu prozessproduzierten Massendaten bzw. ‐akten (etwa staatlichen Verwaltungsdaten und Big Data), wird der Vorzug der theoriegeleiteten Datenerhebung und ‐auswahl betont. Seit den Anfängen der sozialwissenschaftlichen Surveyforschung war die Standardisierung des Forschungsprozesses mit dem Streben nach wissenschaftlicher Objektivität verbunden. Noch heute arbeiten die großen internationalen Forschungsinstitute primär auf der Grundlage von standardisierten Befragungen.
In Vergessenheit geriet im Zuge der erfolgreichen Institutionalisierung der Survey‐Forschung jedoch, dass diese selbst als sozialer Prozess verstanden werden kann. Aus organisations‐ und marktsoziologischer Perspektive erscheint Survey‐Forschung – erstens – als ein Markt, in dem Projekte in komplexen, arbeitsteiligen, transorganisationalen Produktionsketten umgesetzt werden. Die soziale Logik der Herstellung von Wissen beschränkt sich dabei nicht auf die kommerzielle Markt‐ und Meinungsforschung, sondern liegt auch nationalen wie kulturvergleichenden Studien wie ISSP, EVS, ESS, dem World Value Survey usw. zugrunde. In die Wissensproduktion durch die empirische Sozialforschung sind – zweitens – verschiedene soziale Felder (Bourdieu), Konventionen (Ökonomie der Konventionen) und Wissensordnungen (Wissenssoziologie) involviert, die ihren je spezifischen Bewertungsmaßstäben Geltung verschaffen und dadurch konstitutiv für die Prozesse und Produkte der empirischen Sozialforschung sind. Obschon die Legitimation fragebogenbasierter empirischer Sozialforschung sich auf Objektivitäts‐ und Neutralitätspostulaten gründet, wirken ihre Befunde – drittens – auf mannigfaltige Weise in die Gesellschaft zurück. Dieser Zusammenhang von Statistik und Herrschaft ist in die Gründungsgeschichte der Sozialforschung eingeschrieben, wie es Desrosières in seinen historischen Arbeiten oder Boltanski und Thévenot am Beispiel von Berufsklassifikationen aufzuzeigen vermochten.
Dieser Workshop setzt sich zum Ziel, die komplexen Produktionsgefüge fragebogenbasierter Sozialforschung, ihren performativen Charakter und ihre gesellschaftlichen Implikationen kritisch zu reflektieren. Es gilt dabei, Instrumente, Prozesse und Resultate genauer zu betrachten und die für gewöhnlich vernachlässigten Anwendungsbedingungen und Produktionsprinzipien der Survey‐Forschung als dem vermeintlich wissenschaftlich‐neutralen Königsweg soziologischer Methodik offenzulegen. Der Workshop richtet so insgesamt den Fokus auf die Survey‐Forschung als sozialen Prozess. Aus wirtschafts‐ und organisationssoziologischer Perspektive soll etwa thematisiert werden, welche Konventionen die synchrone und diachrone Koordination der Survey‐Produktionskette strukturieren. Aus wissen(schaft)ssoziologischer Perspektive soll die Frage adressiert werden, wie sich der soziale Prozess der Survey‐Forschung in Verfahren, Datenqualität, Messergebnisse und Interpretationen niederschlägt und so hintergründig an der Wissensproduktion konstitutiv beteiligt ist. In herrschaftssoziologischer Absicht soll dann die Frage aufgeworfen werden, wie die empirische Sozialforschung an der Herstellung und Aufrechterhaltung der sozialen Wirklichkeit und der Gesellschaft mitwirkt. Aus methodologischer Perspektive stellt sich schließlich die Frage, inwiefern dieser soziale Prozess der Survey‐Forschung im Alltagshandeln der Forschenden selbst reflektiert werden kann, um den Forschungsprozess zu verbessern und dessen Grenzen aufzuzeigen.
Organisation
Caroline Näther, Andreas Schmitz, Raphael Vogel, Alice Barth und Nina Baur
Zwecks Planung wird um Voranmeldung bis zum 25.05.2017 gebeten.
Programm
Donnerstag, 1. Juni 2017, 13–18.30 Uhr
13.10–14 Uhr
Willkommen, Registrierung und Snacks
14–14.45 Uhr
Begrüßung und Einleitung: Interpretativität und Survey‐Forschung (Nina Baur)
I. Wissen, Praktiken und Konventionen der Survey‐Forschung
15–15.45 Uhr
Beurteilung der Qualität von Survey‐Daten (Jörg Blasius, Universität Bonn)
16–16.45 Uhr
Konstruktäquivalenz und Inhaltsvalidität als besondere Herausforderung in der kulturvergleichenden Forschung (Wolfgang Aschauer, Universität Salzburg)
17–17.45 Uhr
Funktionale Äquivalenz in der interkulturellen Survey‐Forschung –
am Beispiel der Methodenäquivalenz (Martin Weichbold, Universität Salzburg)
18–18.30 Uhr
Abschlussdiskussion des Tag 1 (Moderation: Caroline Näther)
ca. 19 oder 19.30 Uhr
Abendessen im Mar y Sol (Tapas und Spanisches Essen, Savignyplatz 5, 10623 Berlin)
Freitag, 2. Juni 2017, 9–18 Uhr
II. Organisation von Survey‐Forschung
9.30–10 Uhr
Kaffee
10–10.45 Uhr
Die Entscheidung zur Befragungsteilnahme aus der Perspektive soziologischer
Handlungstheorie(n) (Michael Weinhardt, Universität Bielefeld)
11–11.45 Uhr
Surveys als Bestandteil einer Nationalen Forschungsdaten‐Infrastruktur (Stefan Liebig, Universität Bielefeld)
12–12.45 Uhr
Das Hinterland der schweizerischen Survey‐Landschaft. Auf Qualitätskonventionen gestützte Übersetzungs‐ und Koordinationsprozesse entlang der Quality Convention Chain von Surveys (Caroline Näther, Universität Luzern)
12.45–14.30 Uhr
Mittagspause im Manjurani (Indisches Restaurant, Knesebeckstraße 4, 10623 Berlin)
14.30–15.15 Uhr
Die Einbettung von Surveys in Survey‐Welten (Raphael Vogel, Universität Luzern)
III. Macht und Kultur in der Survey‐Forschung
15.30–16.15 Uhr
Prozesse und Mechanismen von Vertrauens‐ und Korruptionskulturen (Peter Graeff, Universität Kiel)
16.30–17.15 Uhr
Meinungsumfrage als ideologische Konsumption – eine feldtheoretische Perspektive (Alice Barth und Andreas Schmitz, Universität Bonn)
17.30 – 18.30 Uhr
Abschlussdiskussion (Moderation: Nina Baur)
19 Uhr
Gemeinsames Abendessen im Restaurantschiff Capt’n Schillow
(Straße des 17. Juni 113)
Ort
Berlin – Institut für Soziologie – Fraunhoferstraße 33‐36 ‐ Raum: FH 919 – 10587 Berlin
Empfohlene Hotels in der Nähe des Veranstaltungsorts
Hotel Otto in der Knesebeckstraße (Entfernung: 750 m, 10 min zu Fuß)
Hotel Indigo Berlin Ku’damm in der Hardenbergstraße (Entfernung: 1 km, 12 Min zu Fuß/Buslinie 245 oder M45: Einstieg: Jebensstr., Ausstieg: Marchstraße, ca. 15 Min)
Novum Style Hotel Berlin‐Centrum in der Franklinstraße (Entfernung: 850 m, 11 Min zu Fuß/Buslinie 245: Einstieg: Franklinstr., Ausstieg: Marchstraße, ca. 15 Min)
Hotel Tiergarten Berlin in Alt‐Moabit (Entfernung: 2,2 km/Buslinie 245: Einsttieg: Turmstraße, Ausstieg: Marchstraße, ca. 20 Min)
Motel One Tiergarten (Entfernung: ca. 3 km, U2: Einstieg: Wittenbergplatz, Ausstieg: Ernst‐Reuter‐Platz, ca. 10 Min)
Motel One Ku’Damm (Entfernung: 1,5 km, Buslinie 245 oder M45: Einstieg: Jebensstr., Ausstieg: Marchstr., ca. 15 Min)
Motel One Hauptbahnhof (Entfernung: ca. 4 km, Buslinie 245: Einstieg: Lesser‐Ury‐Weg, Ausstieg: Marchstraße)
Ich will an dieser Stelle die Gelegenheit nutzen und ein paar Podcasts empfehlen, die sich dem allgemein im Bereich Data Science bewegen. Die Liste ist eine Auswahl und erhebt keinen Anspruch auf Vollständigkeit. Wenn ihr noch weitere Tipps habt, schreibt diese doch in die Kommentare 🙂
Hier die Liste mit den Podcasts (Aktualisiert im Juni 2021):
Mit der ganzen GESIS-Power im Hintergrund widmet sich dieser Podcast dem Thema Forschungsdaten an den unterschiedlichen Stellen des Data Lifecycle: Erhebung, Management, Analyse/Forschungsergebnisse, Archivierung. Eine absolute Hörempfehlung für alle, die an wissenschaftlichen Fakten und Forschungsdaten interessiert sind.
Der CorrelTalk ist der offiziell Podcast des CorrelAid-Netzwerks, das ehrenamtliche Data Scientists miteinander zusammenbringt. In dem Podcast werden sowohl einzelne Projekte vorgestellt, als auch allgemeine Themen aus dem Bereich Data Science besprochen. Der Podcast eignet sich also auch sehr, um sich zu einem möglichen Engagement bei CorrelAid zu informieren.
Data Skeptic
Der Podcast rund um das Thema Data Science erscheint in zwei Formaten: In den Mini-Episoden spricht der Host Kyle mit seiner Frau ganz basal über unterschiedliche statistische Verfahren und Konzepte. Dies ist manchmal vielleicht etwas sehr spielerisch, ich finde es aber insbesondere bei mir unbekannten Methoden sehr gut, um einen ersten Einblick in das Thema zu bekommen.
In den längeren Episoden werden Themen meist ausführlicher behandelt. Hierfür sind häufig sehr interessante Gesprächspartner zu Gast. Neben dem Podcast lohnt sich auch ein Blick in den zugehörigen Blog.
Linear Digressions
Vom Konzept her recht ähnlich zu Data Skeptic. Auch dieser Podcast versucht Data-Science-Themen auf einfache Weise zu beleuchten, geht dabei jedoch nicht so grundsätzliche Themen an wie die Mini-Episoden von Data Skeptic.
Dig Deep
Ein sehr guter deutschsprachiger Podcast, in dem „Neues aus der digitalen Welt” behandelt wird, wie der recht generische Untertitel verspricht. Neben interessanten Beiträgen zum Thema Data Science werden daher auch gesellschaftspolitische Fragestellungen behandelt. Die beiden Hosts Frauke Kreuter und Christof Horn bringen dabei sehr gekonnt ihre unterschiedlichen Perspektiven aus Wissenschaft und freier Wirtschaft ein.
Partially Derivative
Eine Folge dieses ganz hervorragenden Podcasts hatte Arne vor kurzer Zeit bereits gepostet. Der Podcast lebt vor allem von den sehr guten Gästen, die aus ihren jeweiligen Spezialgebieten berichten.
Five Thirty Eight Podcasts
Auf dem bekannten Blog von Nate Silver werden drei Podcasts veröffentlicht, die sich mit inhaltlichen Themen befassen und diese vor dem Hintergrund verschiedener Datenquellen beleuchten. Im Politics Podcasts geht es um aktuelle politische Themen (zumeist aus der amerikanischen Innenpolitik). In Hot Takedown werden Themen aus den US-Sports betrachtet. In What’s the Point geht es eher um allgemeine Fragestellungen bezüglich des Einflusses von Daten auf gesellschaftliche Prozesse.
R-Podcast
Diesen Podcast habe ich erst kürzlich entdeckt und hatte noch keine Gelegenheit ihn ausführlicher zu hören. Er hört sich aber dafür schon sehr interessant an.
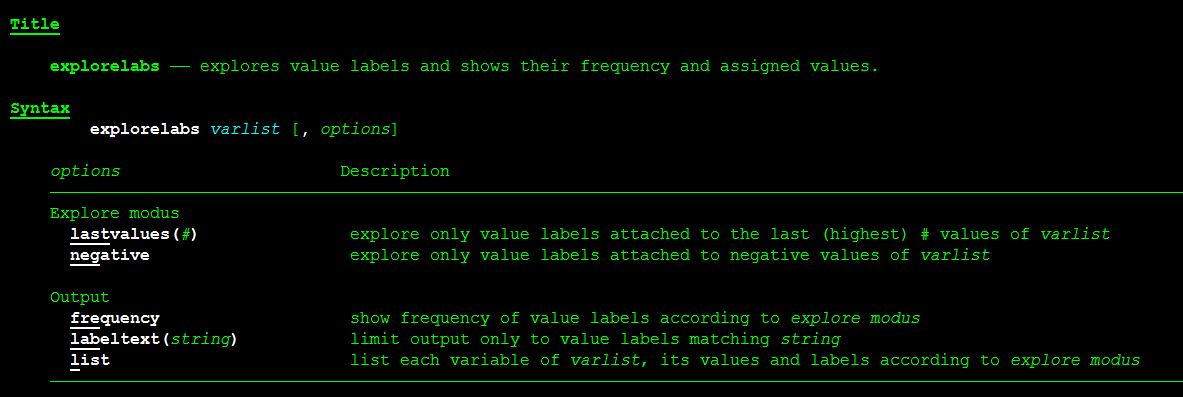
Vor kurzem habe ich ein neues Ado für Stata beim Statistical Software Component Archive (SSC) veröffentlicht, dass den Prozess der Erschließung von Wertelabels in Datensätzen unterstützt. Es heißt EXPLORELABS und kann wie gewohnt mit dem Befehl “ssc install explorelabs” in der Kommandozeile von Stata heruntergeladen werden.
EXPLORELABS ermöglicht dem Nutzer die Wertelabel einer beliebigen Anzahl von Variablen aus dem Datensatz nach bestimmten Mustern zu betrachten. So können entweder alle Werte, nur negative oder nur eine bestimmte Anzahl an letzten/höchsten Werte ausgegeben werden. Zwei Möglichkeiten des Outputs stehen zur Ansicht der gefundenen Wertelabels zur Verfügung: EXPLORELABS – Stata Ado zur Unterstützung in der Erschließung von Labels weiterlesen
Vor der Datendokumentation steht die Erhebung. Für diese Erhebung braucht es Fragen. Fragen werden in der Regel nicht von den Datenproduzenten sondern von den in unserem Kreis als “inhaltlichen Forschern” bezeichneten Kollegen geschrieben.
Die Aufgabe der Fragebogen-Verantwortlichen ist es dann, die vorgelegten Fragen in einen Fragebogen zusammenzustellen und befragbar zu machen. Dabei ist es nicht immer einfach, die “Inhaltlichen” von der Notwendigkeit von Änderungen zu überzeugen. Doch hier kann ein kleines Büchlein helfen.
Der GESIS-Kollege Rolf Porst hat sein gesammeltes Wissen und seine Erfahrung aus der Durchsicht von unzähligen Fragebögen in ein Buch zusammengeschrieben: Fragebogen. Ein Arbeitsbuch. Nicht erst gestern sondern schon 2008 aber ich finde, es verdient (noch) mehr Aufmerksamkeit.
Das Arbeitsbuch ist genau das, eine Handreichung zum praktischen Gebrauch bei der Fragebogengestaltung. Es stehen sehr viele wichtige und ewige Wahrheiten darin, dazu ist es gut lesbar und mit unter 10€ ein echtes Schnäppchen. Zitiert wird es selten, aber das ist der Fluch von Lehrbüchern, die mehr Wert auf Praxistauglichkeit als Autorität legen.
Es eignet sich hervorragen für Nicht-Surveymethodologen und hier kommen wir wieder zur anfänglichen Themenstellung: Wer inhaltlichen Forschern zeigen möchte, was beim Entwurf einer Frage zu beachten ist der kann dieses Buch empfehlen. Oder eine Handvoll kaufen und bei Projektbeginn gleich den Kollegen in die Hand drücken. So kann man schneller zu einer gemeinsamen Arbeitsgrundlage kommen, die inhaltlichen Forscher sehen, dass wir uns die auferlegten Restriktionen nicht zur Schikane ausdenken und Messfehler real sind.
Der Call for Abstracts für den International Total Survey Error Workshop 2017 läuft noch bis zum 26. Februar. Oberthema dieses Jahr ist Total Survey Error: Combined data products from a TSE perspective, oder etwas spezifischer:
In addition to traditional TSE topics, we are encouraging contributions on:
Total error frameworks for Big Data, integrated data sets and products
“Total statistical uncertainty” frameworks for estimates derived from nonprobability samples
Statistical disclosure limitation error
Uses of administrative data to reduce TSE
Methods for addressing specification errors in integrated data sets
Illuminating the Big Data ETL process black box
Wer also (schon wieder) ins schöne Nürnberg zum IAB fahren möchte kann das vom 12. bis 14. Juni tun. Genaue Infos gibt es hier:
Ich würde mich freuen die eine oder den anderen aus unserem Kreis da zu treffen. Schließlich müssen wir ja die Fahne für den Processing Error hochhalten. Ich habe manchmal den Eindruck der ist ein wenig das Stiefkind des TSE-Konzepts 😉
Nach den Erfolgen der ersten beiden DataFeste (2015 und 2016) ziehen die Big Data-affinen Studenten zum 3. DataFest Germany vom 7. bis 9. April 2017 wieder nach Mannheim.
Hier die Beschreibung der Veranstalter:
Das DataFest ist Wettbewerb und interdisziplinäreres Team Event zugleich, bei dem ihr die einzigartige Möglichkeit habt, große Datenmengen zu bearbeiten und nach euren Ideen auszuwerten. Außerdem könnt ihr ganz ungezwungen mit führenden Köpfen der Statistik sowie Unternehmen in Kontakt treten.
Unter dem Dach der American Statistical Association finden viele weitere DataFeste in den USA statt. In den vergangenen Jahren haben wir und unsere amerikanischen Partneruniversitäten bereits sehr gute Erfahrungen gemacht.
…
WAS WIRD DIE AUFGABE SEIN?
Die bereitgestellten Daten sollen eine Überraschung sein und werden erst beim DataFest bekannt gegeben. Soviel sei aber verraten: Geplant ist ein riesiger Datensatz von einem unserer Partner aus der Wirtschaft. In der Vergangenheit wurden beispielsweise Daten vom Los Angeles Police Department daraufhin ausgewertet, wie sich Kriminalität reduzieren lässt. Oder die Daten einer Dating-Website wurden daraufhin untersucht, nach welchen Merkmalen Leute sich ihre künftigen Dates aussuchen. Während der Arbeit kannst du kommen und gehen wie du möchtest. Allerdings ist es nicht erlaubt außerhalb des Veranstaltungsraums am Projekt zu arbeiten. Mindestens zwei Teammitglieder müssen zu Veranstaltungsbeginn anwesend sein.
Präsentiert die Ergebnisse in einer sehr kurzen Präsentation einer bunt gemischten Jury, die sich aus Experten aus verschiedenen Berufsfeldern zusammensetzt. Gewinnen kann man in den Kategorien:
Best Insight
Best Visualization
Best Use of Outside Data
Weitere Details zu Anreise, Anmeldung, Unterkunft und ähnlichem gibt es unter:
Im aktuellen Newsletter DDI DIRECTIONS der DDI Alliance, der insbesondere über die Mailingliste [DDI-users] versandt wird, ist wieder die Kolumne Read-Write-Execute (RWX) erschienen, die auf wissenschaftliche Publikationen aus dem Bereich Metadaten hinweisen will:
DDI DIRECTIONS: Logo of the DDI Alliance’s Newsletter
The DDI Community has produced a rich store of DDI and metadata-related publications. Read-Write-Execute (RWX) will highlight some of these existing publications as well as new work as it is produced. The first column featured some of the foundations of DDI in scientific literature. This second column will revisit some of the top impact publications related to DDI from the last 20 years.
It is not surprising that the DDI publications with many citations cover more high level discussions rather than specific technical details. But revisiting conceptual fundamentals or policy goals, comparing standards, and evaluating approaches should also be done if one is currently planning the next project. So, let’s take a look at some of the top cited DDI publications over the last 20 years.
When Ryssevik and Musgrave (2001) write about their social science dream machine, they were thinking about the distributed NESSTAR system, which is based on DDI. But there is nothing wrong with the idea of an “integrated resource discovery gateway and search system to identify and locate these resources” which consists of not less than “all existing empirical data” (what is today called federated search). And being able to convert an “extensive amount of metadata … totally integrated with the data as such” to a number of formats and copy them to a local machine is a reasonable wish. The same holds true with “an efficient feedback system to the body of metadata, allowing the user to add to the collecting memory of a data set”. Even “The FAIR Guiding Principles for scientific data management and stewardship” (doi:10.1038/sdata.2016.18) from 2016, which are considered to be state of the art, do not cover the range of features Ryssevik and Musgrave describe.
The most cited publication in 2004 contains an important reminder: “Technology itself, however, will not fulfill the promise of e-science, Information and communication technologies provide the physical infrastructure. It is up to national governments, international agencies, research institutions, and scientists themselves to ensure the institutional, financial and economic, legal, and cultural and behavioural aspects of data sharing are taken into account.” (Arzberger et al. 2004: 137) The use of DDI, especially at ICPSR, serves as a use case for the technological domain where access and usability and multiple use of the data must be assured by interoperability.
While Arzberger et al. look at use cases from different disciplines in the different identified domains, Willis, Greenberg and White (2012) compare nine metadata standards in order to understand similarities and differences. They consider DDI as the standard to describe social science statistical data from experimental, observational, and statistical studies. The objective to cover the whole data lifecycle is unique to DDI. DDI is one of two standards which “are intended to be comprehensive, yet support instances of description using a minimal number of required elements.” They conclude that metadata scheme creation depends more on the goals than on the discipline or type of data described (p.1517). At the same time the common discipline specific approach contributes “to artificial boundaries between disciplines and impede interdisciplinary and transdisciplinary reuse” (p. 1516).
For Jeffrey et al. (2014), who describe the CERIF approach to design a research information management system, domain specific metadata standards build the lowest of three levels of information. The first level consists of information on research output (organized by flat metadata like Dublin Core similar to a catalogue card). The second level is built by contextual metadata, which can generate the discovery metadata of level one and point to the domain metadata of level three (which could be DDI). The contextual metadata hold information about base entities (e.g., persons and publications) and connect them using a semantic layer with flexible link entities, which can express roles (defined by a term which captures the semantics and a controlled vocabulary to which the term belongs (p. 10) and have a start and end date). Using this semantic layer a publication can have an author, a publication date, and even a country of publication (using so called localisation entities).
This small list of four top publications related to DDI:
shows us that looking more than 15 years back might yield new insights into new products from old ideas,
reminds us that technology does not solve social problems,
reveals different perspectives on the discipline specific fragmentation of metadata standards,
and gives an insight into a concept of a flexible and expressive linking mechanism.
Arzberger, P., Schroeder, P., Beaulieu, A., Bowker, G., Casey, K., Laaksonen, L., Moorman, D., Uhlir, P. & Wouters, P. (2004). Promoting Access to Public Research Data for Scientific, Economic, and Social Development. Data Science Journal, 3, 135-152. doi:10.2481/dsj.3.135
Jeffery, K., Houssos, N., Jörg, B. & Asserson, A. (2014). Research Information management: the CERIF approach. International Journal of Metadata, Semantics and Ontologies, 9, 5-14. doi:10.1504/ijmso.2014.059142
Ryssevik, J. & Musgrave, S. (2001). The Social Science Dream Machine: Resource Discovery, Analysis, and Delivery on the Web. Social Science Computer Review, 19, 163-174. doi:10.1177/089443930101900203
Willis, C., Greenberg, J. & White, H. (2012). Analysis and Synthesis of Metadata Goals for Scientific Data. Journal of the American Society for Information Science and Technology, 63, 1505–1520. doi:10.1002/asi.22683
A bibliography of DDI articles, working papers, and presentations is being built and is available at Bibsonomy.org with easily reusable bibliographic metadata. This metadata will also be made available on the DDI Alliance website. Suggestions for papers and topics for RWX, or the bibliography, are appreciated and can be sent to: Knut Wenzig, kwenzig@diw.de