Der Call for Abstracts für den International Total Survey Error Workshop 2017 läuft noch bis zum 26. Februar. Oberthema dieses Jahr ist Total Survey Error: Combined data products from a TSE perspective, oder etwas spezifischer:
In addition to traditional TSE topics, we are encouraging contributions on:
Total error frameworks for Big Data, integrated data sets and products
“Total statistical uncertainty” frameworks for estimates derived from nonprobability samples
Statistical disclosure limitation error
Uses of administrative data to reduce TSE
Methods for addressing specification errors in integrated data sets
Illuminating the Big Data ETL process black box
Wer also (schon wieder) ins schöne Nürnberg zum IAB fahren möchte kann das vom 12. bis 14. Juni tun. Genaue Infos gibt es hier:
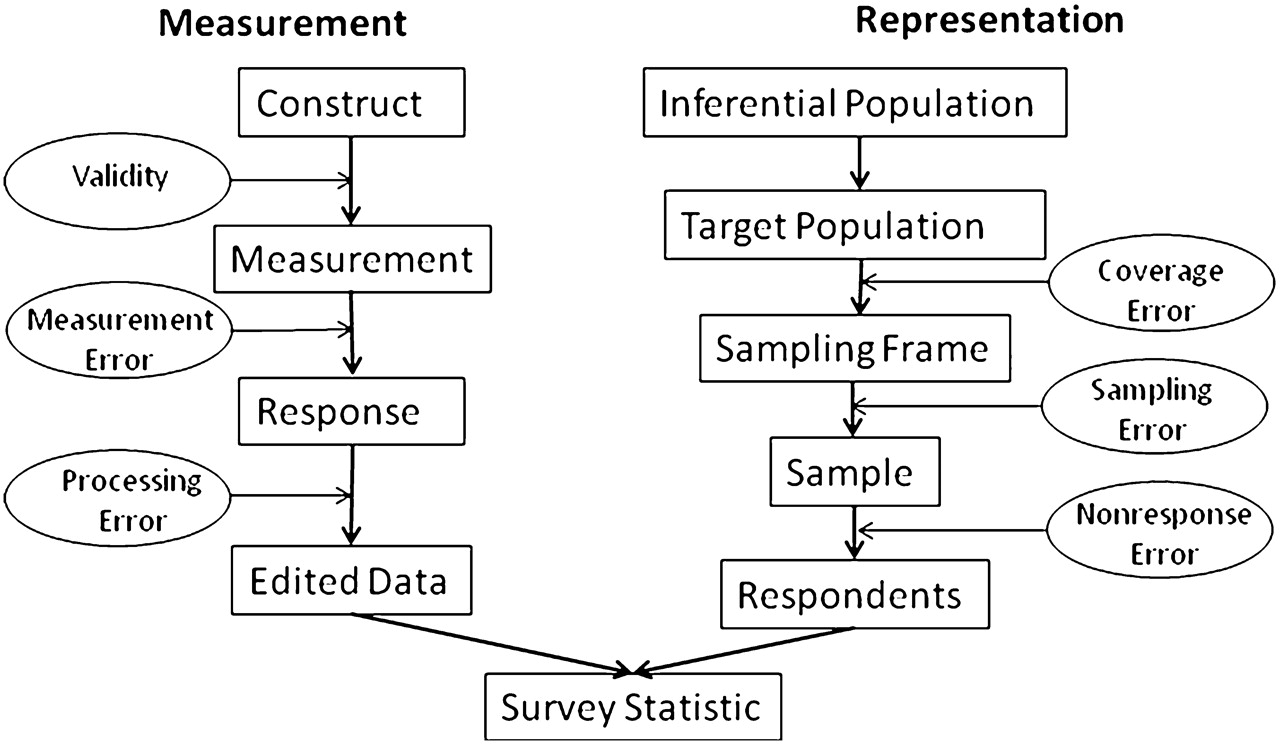
Ich würde mich freuen die eine oder den anderen aus unserem Kreis da zu treffen. Schließlich müssen wir ja die Fahne für den Processing Error hochhalten. Ich habe manchmal den Eindruck der ist ein wenig das Stiefkind des TSE-Konzepts 😉
Nach den Erfolgen der ersten beiden DataFeste (2015 und 2016) ziehen die Big Data-affinen Studenten zum 3. DataFest Germany vom 7. bis 9. April 2017 wieder nach Mannheim.
Hier die Beschreibung der Veranstalter:
Das DataFest ist Wettbewerb und interdisziplinäreres Team Event zugleich, bei dem ihr die einzigartige Möglichkeit habt, große Datenmengen zu bearbeiten und nach euren Ideen auszuwerten. Außerdem könnt ihr ganz ungezwungen mit führenden Köpfen der Statistik sowie Unternehmen in Kontakt treten.
Unter dem Dach der American Statistical Association finden viele weitere DataFeste in den USA statt. In den vergangenen Jahren haben wir und unsere amerikanischen Partneruniversitäten bereits sehr gute Erfahrungen gemacht.
…
WAS WIRD DIE AUFGABE SEIN?
Die bereitgestellten Daten sollen eine Überraschung sein und werden erst beim DataFest bekannt gegeben. Soviel sei aber verraten: Geplant ist ein riesiger Datensatz von einem unserer Partner aus der Wirtschaft. In der Vergangenheit wurden beispielsweise Daten vom Los Angeles Police Department daraufhin ausgewertet, wie sich Kriminalität reduzieren lässt. Oder die Daten einer Dating-Website wurden daraufhin untersucht, nach welchen Merkmalen Leute sich ihre künftigen Dates aussuchen. Während der Arbeit kannst du kommen und gehen wie du möchtest. Allerdings ist es nicht erlaubt außerhalb des Veranstaltungsraums am Projekt zu arbeiten. Mindestens zwei Teammitglieder müssen zu Veranstaltungsbeginn anwesend sein.
Präsentiert die Ergebnisse in einer sehr kurzen Präsentation einer bunt gemischten Jury, die sich aus Experten aus verschiedenen Berufsfeldern zusammensetzt. Gewinnen kann man in den Kategorien:
Best Insight
Best Visualization
Best Use of Outside Data
Weitere Details zu Anreise, Anmeldung, Unterkunft und ähnlichem gibt es unter:
Im aktuellen Newsletter DDI DIRECTIONS der DDI Alliance, der insbesondere über die Mailingliste [DDI-users] versandt wird, ist wieder die Kolumne Read-Write-Execute (RWX) erschienen, die auf wissenschaftliche Publikationen aus dem Bereich Metadaten hinweisen will:
DDI DIRECTIONS: Logo of the DDI Alliance’s Newsletter
The DDI Community has produced a rich store of DDI and metadata-related publications. Read-Write-Execute (RWX) will highlight some of these existing publications as well as new work as it is produced. The first column featured some of the foundations of DDI in scientific literature. This second column will revisit some of the top impact publications related to DDI from the last 20 years.
It is not surprising that the DDI publications with many citations cover more high level discussions rather than specific technical details. But revisiting conceptual fundamentals or policy goals, comparing standards, and evaluating approaches should also be done if one is currently planning the next project. So, let’s take a look at some of the top cited DDI publications over the last 20 years.
When Ryssevik and Musgrave (2001) write about their social science dream machine, they were thinking about the distributed NESSTAR system, which is based on DDI. But there is nothing wrong with the idea of an “integrated resource discovery gateway and search system to identify and locate these resources” which consists of not less than “all existing empirical data” (what is today called federated search). And being able to convert an “extensive amount of metadata … totally integrated with the data as such” to a number of formats and copy them to a local machine is a reasonable wish. The same holds true with “an efficient feedback system to the body of metadata, allowing the user to add to the collecting memory of a data set”. Even “The FAIR Guiding Principles for scientific data management and stewardship” (doi:10.1038/sdata.2016.18) from 2016, which are considered to be state of the art, do not cover the range of features Ryssevik and Musgrave describe.
The most cited publication in 2004 contains an important reminder: “Technology itself, however, will not fulfill the promise of e-science, Information and communication technologies provide the physical infrastructure. It is up to national governments, international agencies, research institutions, and scientists themselves to ensure the institutional, financial and economic, legal, and cultural and behavioural aspects of data sharing are taken into account.” (Arzberger et al. 2004: 137) The use of DDI, especially at ICPSR, serves as a use case for the technological domain where access and usability and multiple use of the data must be assured by interoperability.
While Arzberger et al. look at use cases from different disciplines in the different identified domains, Willis, Greenberg and White (2012) compare nine metadata standards in order to understand similarities and differences. They consider DDI as the standard to describe social science statistical data from experimental, observational, and statistical studies. The objective to cover the whole data lifecycle is unique to DDI. DDI is one of two standards which “are intended to be comprehensive, yet support instances of description using a minimal number of required elements.” They conclude that metadata scheme creation depends more on the goals than on the discipline or type of data described (p.1517). At the same time the common discipline specific approach contributes “to artificial boundaries between disciplines and impede interdisciplinary and transdisciplinary reuse” (p. 1516).
For Jeffrey et al. (2014), who describe the CERIF approach to design a research information management system, domain specific metadata standards build the lowest of three levels of information. The first level consists of information on research output (organized by flat metadata like Dublin Core similar to a catalogue card). The second level is built by contextual metadata, which can generate the discovery metadata of level one and point to the domain metadata of level three (which could be DDI). The contextual metadata hold information about base entities (e.g., persons and publications) and connect them using a semantic layer with flexible link entities, which can express roles (defined by a term which captures the semantics and a controlled vocabulary to which the term belongs (p. 10) and have a start and end date). Using this semantic layer a publication can have an author, a publication date, and even a country of publication (using so called localisation entities).
This small list of four top publications related to DDI:
shows us that looking more than 15 years back might yield new insights into new products from old ideas,
reminds us that technology does not solve social problems,
reveals different perspectives on the discipline specific fragmentation of metadata standards,
and gives an insight into a concept of a flexible and expressive linking mechanism.
Arzberger, P., Schroeder, P., Beaulieu, A., Bowker, G., Casey, K., Laaksonen, L., Moorman, D., Uhlir, P. & Wouters, P. (2004). Promoting Access to Public Research Data for Scientific, Economic, and Social Development. Data Science Journal, 3, 135-152. doi:10.2481/dsj.3.135
Jeffery, K., Houssos, N., Jörg, B. & Asserson, A. (2014). Research Information management: the CERIF approach. International Journal of Metadata, Semantics and Ontologies, 9, 5-14. doi:10.1504/ijmso.2014.059142
Ryssevik, J. & Musgrave, S. (2001). The Social Science Dream Machine: Resource Discovery, Analysis, and Delivery on the Web. Social Science Computer Review, 19, 163-174. doi:10.1177/089443930101900203
Willis, C., Greenberg, J. & White, H. (2012). Analysis and Synthesis of Metadata Goals for Scientific Data. Journal of the American Society for Information Science and Technology, 63, 1505–1520. doi:10.1002/asi.22683
A bibliography of DDI articles, working papers, and presentations is being built and is available at Bibsonomy.org with easily reusable bibliographic metadata. This metadata will also be made available on the DDI Alliance website. Suggestions for papers and topics for RWX, or the bibliography, are appreciated and can be sent to: Knut Wenzig, kwenzig@diw.de
Seit einer kurzen Weile hat der Workshop “Datenproduktion und Datenmangement“ eine Mailingliste.
Diese Liste soll zwischen den Workshops zum Austausch der Mitglieder über die namensgebenden Themen ermöglichen. Einfach selbst bei der [Datenproduktion] anmelden und bei Bedarf eine E-Mail an die Liste absetzten.
Wir nutzen die Mailingliste auch für Ankündigungen zu den nächsten Workshop-Terminen, diese Ankündiungen werden auch hier auf dem Blog erscheinen.
Ziel des Workshops ist der lösungsorientierte, praktische Austausch über Fragestellungen in der Detendokumentation und -produktion in sozialwissenschaftlichen Studien. Das Format wird wieder nach dem Modell der Open Space Conference ohne vorher festgelegtes Programm durchgeführt.
Alle Teilnehmenden sollten sich im Vorfeld Themen überlegen, die sie gerne vorstellen möchten oder die sie gerne besprechen wollen. Alle Teilnehmenden bringen sich aktiv in den Workshop ein. Die Agenda wird dann vor Ort festgelegt.
Sprache: Die Sprache des Workshops war bisher deutsch. Sollte das Probleme bereiten melden Sie sich bitte.
Zielgruppe: Der Workshop richtet sich an Mitarbeiterinnen und Mitarbeiter sozialwissenschaftlicher Studien, die mit der Datendokumentation und Datenproduktion beschäftigt sind. Der Workshop hat einen mehr oder weniger festen Kreis von Teilnehmenden. Für sinnvolle Ergänzungen sind wir aber durchaus offen.
Anmeldung
Hier kann man sich für den Workshop Datenproduktion und Datendokumentation und/oder den Workshop der Panelsurveys in Deutschland anmelden.
Verpflegung
Die Verpflegung während der Veranstaltung wird vom IAB bereitgestellt. Geplant sind außerdem gemeinsame Abendessen (Selbstzahler) am 20. und 21.Februar. Wir würden uns freuen, wenn Sie daran teilnehmen würden (nähere Informationen dazu erhalten Sie während des Workshops).
Hotels
Für den Workshop wurden Zimmerkontingente reserviert:
Bis zum 15. Januar 2017 steht ein Einzelzimmer-Kontingent im B&B Hotel zur Verfügung. Die Kosten betragen 59,00€ pro Zimmer/Nacht (auf Wunsch kann zusätzlich ein Frühstücksbuffet zum Preis von 8,50€ gebucht werden). Bei der Reservierung bitte das Stichwort „IAB PASS“ und/oder die Reservierungsnummer 66359099 angeben.
Auch das Ramada Hotel hält ein Kontingent bereit. Bis 6. Februar 2017 können Sie unter dem Stichwort „IAB PASS“ Einzelzimmer zum Preis von 88,00€ pro Zimmer/Nacht buchen.
We would like to announce the 15th German Stata Users Group meeting to be held Friday, June 23, 2017 at Humboldt University Berlin, Grimm-Zentrum, Geschwister-Scholl-Straße 1, 10117 Berlin.
All Stata users, from Germany and elsewhere, or those interested in learning about Stata, are invited to attend.
Presentations are sought on topics that include the following:
User-written Stata programs
Case studies of research or teaching using Stata
Discussions of data management problems
Reviews of analytic issues
Surveys or critiques of Stata facilities in specific fields, etc.
The conference language will be English, due to the international nature of the meeting and the participation of non-German guest speakers.
Submission guidelines
If you are interested in presenting a paper, please submit an abstract by email to one of the scientific organizers (max 200 words). The deadline for submissions is March 1, 2017. Presentations should be 20 minutes or shorter.
Registration
Participants are asked to travel at their own expense. There will be a small conference fee to cover costs for refreshments and lunch. There will also be an optional informal meal at a restaurant in Berlin on Friday evening at additional cost.
You can enroll by contacting Christiane Senczek by email or by writing or phoning.
Dittrich & Partner Consulting GmbH (dpc.de), the distributor of Stata in several countries, including Germany, the Netherlands, Austria, the Czech Republic, and Hungary.
Simon Munzert schreibt auf Soziopolis, warum Programmierkenntnisse – vorzugsweise mit R – im Rahmen der sozialwissenschaftlichen Methodenausbildung zum Curriculum gehören sollten.
The 43rd annual conference of the International Association for Social Science Information Services and Technology (IASSIST) will be held in Lawrence, Kansas from May 23-26, 2017.
Many issues around data (sources, strategies, and tools) are similar across disciplines. While IASSIST has its roots in social science data, it has also welcomed discussions over the years of other disciplines’ issues as they relate to data, data management, and support of users. So again this year, in line with this tradition, we are arranging a conference that will benefit those who support researchers across all disciplines: social sciences, health and natural sciences, and humanities. Please join the international data community in Lawrence, KS, “in the middle” of the U.S., for insights and discussion on how data in all disciplines are found, shared, used, and managed. Join us and draw inspiration from this diverse gathering!
We welcome submissions for papers, presentations, panels, posters, and pecha kuchas.