Der Survey Lifecycle Operators Workshop (SLOW) findet im Jahr 2026 vermutlich vom 20. bis 22. April 2026 statt.
EDDI2025: Call for Proposals
Die EDDI2025 wird vom Forschungsdokumentationszentrum am Zentrum für Sozialwissenschaften HUN-REN in Budapest von Montag, dem 1. Dezember bis Freitag, dem 5. Dezember 2025 als Präsenzveranstaltung ausgerichtet:
- Tutorials und Workshops: Montag, 1. Dezember 2025
- Konferenz: Dienstag, 2. Dezember – Mittwoch, 3. Dezember 2025
- Begleitveranstaltungen: Donnerstag, 4. Dezember – Freitag, 5. Dezember 2025
Die Data Documentation Initiative (DDI) ist ein internationaler Standard zur Beschreibung von Daten, die durch Umfragen und andere beobachtende Methoden in den Sozial-, Verhaltens-, Wirtschafts- und Gesundheitswissenschaften erhoben werden.
Die Veranstaltung bringt DDI-Nutzer*innen und Fachleute aus ganz Europa und der Welt zusammen. Alle, die daran interessiert sind, DDI zu entwickeln, anzuwenden, zu hinterfragen oder zu nutzen, sind herzlich eingeladen, teilzunehmen und Beiträge zu präsentieren.
Gesucht werden Beiträge zu allen Aspekten von DDI, darunter:
- Fallstudien
- Ausgereifte Implementierungen
- Erste Implementierungen
- Zusammenspiel von DDI mit anderen Standards oder Technologien
- Projekte in frühen Phasen, in denen DDI in Betracht gezogen wird
- Kritiken an DDI
- Aktivitäten zum Aufbau der Community
Der Call for Proposals ist veröffentlicht und endet am 1. September 2025.
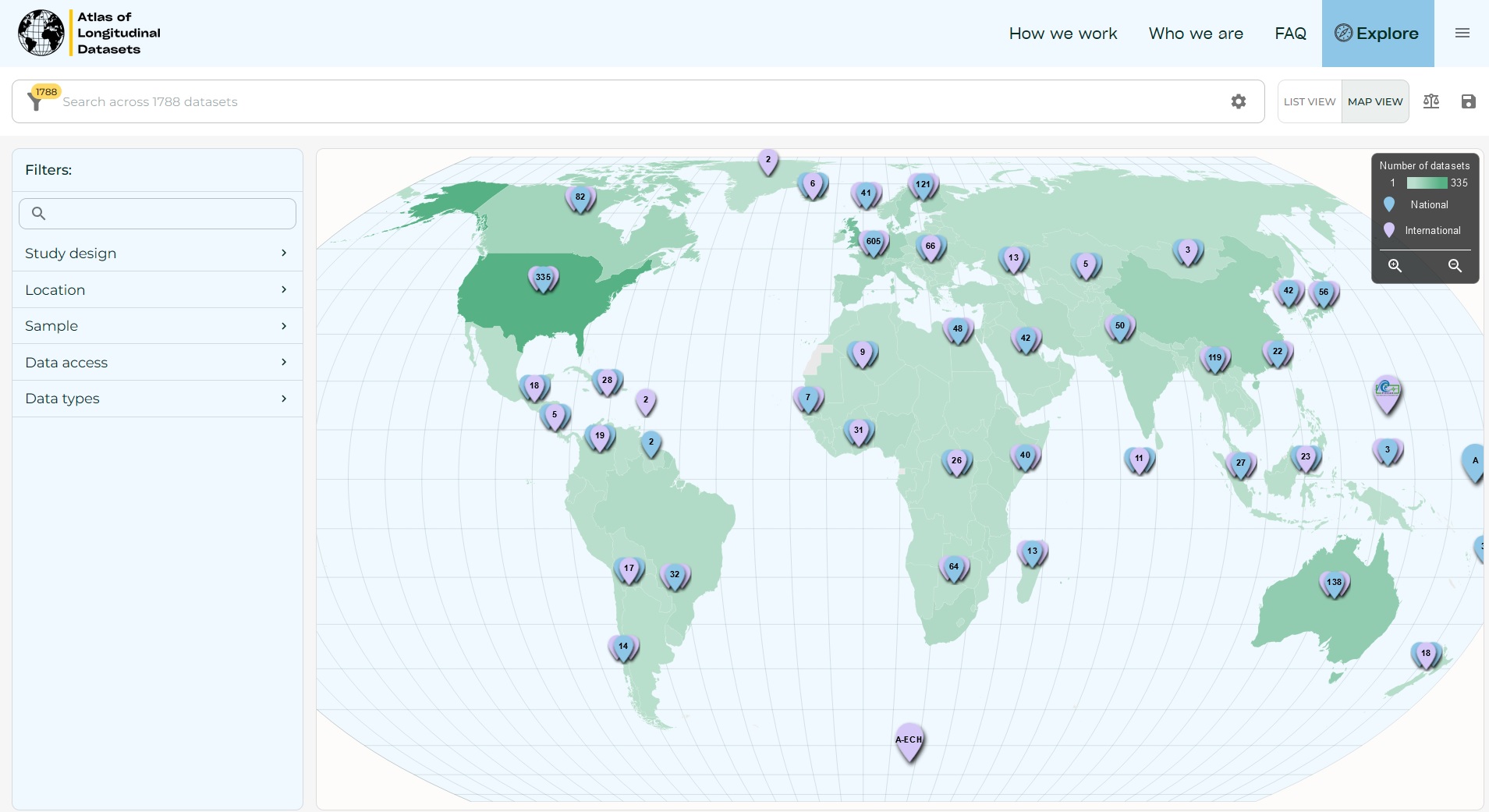
Atlas/Datenbank longitudinaler Erhebungen/Datensätze
Unter https://atlaslongitudinaldatasets.ac.uk ist 2023 ein Projekt gestartet, welches zum Ziel hat, longitudinale Studien bzw. deren Datensätze auffindbar zu machen. Derzeit verfügt das Projekt über Kenntnisse zu ca. 3.600 Datensätzen weltweit, davon sind ca. 1.600 in dem Atlas bereits publiziert.
Der Atlas übernimmt die Erfassung der Daten selbst, um Einheitlichkeit zu gewährleisten. Ob eigene Studie schon erfasst ist, kann unter atlas.longitudinaldatasets@kcl.ac.uk erfragt werden.
Der Startschwerpunkt der Datenbank war Mental Health.
TREE, Universität Bern, sucht eine Leiterin / einen Leiter des Data Managements
TREE (Transitions from Education to Employment) sucht ein:e Nachfolger:in der jetzigen Stelleninhaberin als Leiter:in des Data Managements. Hier sind die Links zur Stellenausschreibung und zur TREE-Website:
SHARE sucht Mitarbeiter*innen für die Abteilungen Data Base Management und Questionnaire Development
Liebe Survey Data Community,
wir brauchen dringend Verstärkung und freuen uns auf eure Bewerbungen. Die Ausschreibungen findet ihr hier:
https://share-eric.eu/news-events/job-offers
Bei Fragen zur Data Base Management Stelle könnt ihr euch gerne and Stephanie Stuck (sstuck@share-berlin.eu) wenden, für die Stelle im Questionnaire Development Team an Theresa Fabel (tfabel@share-berlin.eu)
DataFest 2025 – Anmeldung läuft
Wie jedes Jahr findet auch 2025 vom 28. bis 30. März wieder ein DataFest statt! Ein Hackathon für Bachelor- und Masterstudierende, bei dem sie sich mit Gleichgesinnten an einem vorher unbekannten Datensatz austoben können. Ziel ist es innerhalb von 48h die interessantesten Analysen, die schönsten Visualisierungen und die trickreichsten Modellierungen zu entwickeln.
Organisiert wird das Ganze gemeinsam vom Social Data Science and AI Lab (SODA) der Ludwig-Maximilians-Universität München und der Fakultät für Sozialwissenschaften der Universität Mannheim. Die Anmeldung läuft noch bis zum 1. März 2025. Wer also noch Leute kennt, die vielleicht teilnehmen mögen: weitersagen! Meine studentische Hilfskraft war jedenfalls begeistert 🙂
Call for Participation: Stichwort Programmiertestung – Wie ist die Surveypraxis?

Beim SLO-Workshop in Mannheim hat sich eine Gruppe gebildet, die sich zunächst einen Überblick über die Praxis der Programmiertestung in Surveys verschaffen will. Daraus kann dann ein gemeinsames Verständnis darüber entwickeln, was unter Programmiertestung verstanden werden soll und welche Empfehlungen gegeben werden können.
In einem ersten Schritt soll jede interessierte Studie bzw. jedes interessierte Institut beschreiben, wie die Programmiertestung abläuft. Hierzu soll auch Material zur Verfügung gestellt werden, das in dem Zusammenhang genutzt bzw. erstellt wird (z.B. Checklisten für Hiwis, Filter-Diagramme/Bäume, Fehlerlogs). Auch die Testung von Preloads, kann thematisiert werden. Idealerweise soll das Vorgehen auf etwa einer Textseite beschrieben werden, was mit weiterem Material illustriert werden kann. Auch Literaturhinweise sind willkommen. Die Beschreibungen sollen bis 16. März bei Knut Wenzig eingehen.
Dieses Material soll dann gemeinsam gesichtet und diskutiert werden. Im weiteren Verlauf könnte über die Rolle von Metadaten in diesem Prozess diskutiert werden und am Ende könnte eine Veröffentlichung der Arbeitsergebnisse etwa in der Zeitschrift Bausteine Forschungsdatenmanagement stehen.
Interesse an der Bearbeitung dieses Themas wurde von Kolleg*innen aus LIfBi, dem DJI, TREE, IAB, SHARE, GESIS und DIW Berlin gezeigt.
Bericht vom SLOW2025 in Mannheim
Mit Unterstützung von BERD und KonsortSWD hat an der Universität Mannheim vom 3. bis 5. Februar 2025 der Survey Lifecycle Operators Workshop stattgefunden. Das großartige Local Organizing Team stammte aus Bibliothek und GIP. Gekommen waren 65 Menschen, die für 21 Studien im deutschsprachigen Raum arbeiten.
In bewährter Open-Space-Technologie wurde ein anspruchsvolles Workshop-programm organisiert.


Hier ein Überblick über die Inhalte der Sessions:
In der Session „Pre-Session, Dokumentation“ wurde zu Beginn des Workshops die Bedeutung zentraler Dokumentationsansätze betont. Es ging um den Einsatz von Datenbank-Tools und „Meta-Dokumenten“, um den schnellen Zugriff auf wichtige Informationen zu ermöglichen. Gleichzeitig stand ein offenes Fehlermanagement sowie der Austausch von Learnings im Mittelpunkt. Die Diskussion legte den Grundstein für eine strukturierte Arbeitsweise im weiteren Verlauf.
In der Session „Panel und Linkage Consent, Panelstabilität“ wurden Strategien zur Erhöhung der informierten Einwilligung thematisiert. Die Teilnehmenden diskutierten, wie Zuspiel- und Panelbereitschaft optimal abgefragt werden können, um eine hohe Datenqualität zu sichern. Verschiedene Ansätze zur Platzierung der Consent-Anfragen sowie der Umgang mit Interviewabbrüchen wurden kritisch beleuchtet. Ergänzend lieferten Praxisbeispiele und Literaturhinweise wichtige Anknüpfungspunkte für die Optimierung der Erhebungsmethoden.
Die Session „(interne) Dokumentation“ fokussierte auf den internen Austausch und die Wissenssicherung. Die Diskussion drehte sich um den Einsatz von Projektmanagement- und Kollaborationstools sowie den Vergleich zu manuell strukturierten Verzeichnisstrukturen. Es wurde erörtert, wie durch klare Benennungskonventionen und regelmäßige Abstimmungen ein reibungsloser Informationsfluss gewährleistet werden kann. Die Teilnehmenden waren sich einig, dass eine solide interne Dokumentation essenziell ist.
In der Session „Austausch/Transfer von Metadaten“ stand die Rolle standardisierter Metadaten im Lifecycle von Surveys im Vordergrund. Es wurde diskutiert, wie bisher ungenutzte Metadaten systematisch erfasst und durch KI-basierte Ansätze besser zugänglich gemacht werden können. Unterschiedliche Standards wie DDI Codebook und DDI Lifecycle wurden miteinander verglichen. Das Ziel war, einen einheitlichen Standard zur Steigerung des Datenmehrwerts zu etablieren.
Die Session „Soziodemographie und sozialer Wandel“ behandelte die Weiterentwicklung soziodemographischer Standarditems. Die Diskussion hob hervor, dass traditionelle Messinstrumente kontinuierlich an den sozialen Wandel – insbesondere in Bezug auf Geschlecht und Migration – angepasst werden müssen. Vorschläge zur Vereinfachung und Harmonisierung verschiedener Fragebögen wurden intensiv erörtert. Die Teilnehmenden strebten eine zukunftsfähige und valide Datengrundlage an.
In der Session „Situation/Landschaft der Erhebungsinstitute“ wurden strukturelle Veränderungen in der Erhebungslandschaft thematisiert. Es ging um die Auswirkungen von Fusionen und organisatorischen Umstrukturierungen auf Qualität, Angebot und Preisgestaltung der Umfragedienstleistungen. Zudem wurde der Trend zu selbstadministrierten Erhebungen kritisch diskutiert. Dabei rückte die Bedeutung einer flexiblen Infrastruktur in den Fokus.
Die Session „Sampling, Rekrutierung und Gewichtung“ setzte sich mit den methodischen Herausforderungen im Sampling auseinander. Es wurden Techniken des Oversamplings sowie die Integration variierender Designgewichte beleuchtet. Verschiedene Ansätze zur Rekrutierung und Incentivierung von Befragten wurden vorgestellt. Praktische Erfahrungen zeigten, wie diese Herausforderungen erfolgreich gemeistert werden können.
In der Session „(innovative) Incentivierung“ wurden kreative Ansätze zur Steigerung der Teilnahmebereitschaft diskutiert. Die Teilnehmenden stellten unkonventionelle Maßnahmen wie personalisierte Neujahrskarten, Sondermünzen und direkte Ergebnisrückmeldungen vor. Es wurde erörtert, wie innovative Incentive-Modelle langfristig die Motivation der Teilnehmenden erhöhen können. Erste Experimente mit Prepaid-Incentives lieferten interessante Impulse.
Die Session „Paradaten“ widmete sich dem Potenzial ungenutzter Metadaten. Es wurde diskutiert, wie Paradaten systematisch aufbereitet und ausgewertet werden können, um interne Analysen zu verbessern. Herausforderungen bei der Vergleichbarkeit und Standardisierung dieser Daten wurden angesprochen. Die Diskussion offenbarte neue Möglichkeiten zur Optimierung interner Datenprozesse.
In der Session „Automatisierte Programmiertestung“ ging es um die Überprüfung der programmierten Logik in Befragungsinstrumenten. Die Teilnehmenden diskutierten, inwieweit automatisierte Testverfahren konzeptionelle Fehler erkennen können. Vorschläge wie die automatische Generierung von Testcases und visuelle Entscheidungsbäume wurden als Ergänzung zu manuellen Tests vorgestellt. Es wurde erkannt, dass automatisierte Ansätze ein wertvolles, wenn auch ergänzendes Werkzeug darstellen.
Die Session „Ethikkommission“ beschäftigte sich mit der Rolle und Organisation von Ethikprüfungen in der Surveyforschung. Es wurde erörtert, in welchem Umfang einzelne Module oder komplette Studien einer ethischen Prüfung bedürfen. Die Diskussion hinterfragte, wer als Ethikkommission agieren kann und welche Verfahren zielführend sind. Dabei wurde die Balance zwischen umfassender Prüfung und praktischer Umsetzbarkeit thematisiert.
In der Session „Datenzugang sensible Daten / Mögliche Quellen zur Anreicherung von Befragungsdaten“ stand der sichere Zugang zu sensiblen Daten im Mittelpunkt. Es wurden Strategien zur Pseudonymisierung und getrennten Bereitstellung von Befragungs- und Kontaktdaten diskutiert. Verschiedene Best-Practice-Beispiele, etwa im Umgang mit Geodaten, wurden vorgestellt. Ziel war es, einerseits den Datenschutz zu gewährleisten und andererseits den Nutzwert der Daten zu steigern.
Die Session „Teilnehmer:innen Motivation“ thematisierte Maßnahmen zur Steigerung der Motivation der Panelteilnehmenden. Kreative Mitmachaktionen – von analogen Bildwettbewerben bis zu digitalen Vorbefragungen – wurden als Mittel zur Panelpflege vorgestellt. Es wurde betont, dass sowohl der Erstkontakt als auch kontinuierliche Anreize entscheidend sind. Die Diskussion zeigte, wie vielfältige Ansätze zur langfristigen Bindung beitragen können.
In der Session „Qualitative Aspekte der Survey Methodology“ lag der Schwerpunkt auf der Ergänzung quantitativer Methoden durch qualitative Pretests. Die Teilnehmenden diskutierten, wie qualitative Interviews und interaktive Pretests dazu beitragen können, die Wirkung von Frageformulierungen besser zu verstehen. Kommunikationsstrategien und die Gestaltung von Studientiteln sowie Anschreiben wurden ebenfalls erörtert. Es wurde betont, dass selbst suboptimale Pretests wertvolle Erkenntnisse liefern.
Die Session „Messung Geschlecht“ fokussierte auf die Herausforderungen der Geschlechtererfassung in Umfragen. Es wurden sowohl biologische als auch soziale Dimensionen von Geschlecht diskutiert und Ansätze zur Integration nicht-binärer Kategorien vorgestellt. Die Teilnehmenden erörterten, wie durch differenzierte Fragestellungen Diskriminierungserfahrungen besser abgebildet werden können. Ziel war es, flexible und inklusive Messinstrumente zu entwickeln.
In der Session „KI“ wurden die Einsatzmöglichkeiten von Künstlicher Intelligenz in der Surveyforschung beleuchtet. Es ging um den praktischen Einsatz von KI bei der Datendokumentation, Fragebogenentwicklung und Auswertung offener Antworten. Chancen und Limitationen der Technologie wurden offen diskutiert, wobei auch institutionelle Richtlinien eine Rolle spielten. Die Diskussion zeigte das Potenzial von KI, traditionelle Arbeitsprozesse zu ergänzen.
Die Session „Datenlöschungen von Befragten“ befasste sich mit der Umsetzung von Löschprozessen im Rahmen der Datenschutz-Grundverordnung. Es wurde diskutiert, ob nur Kontaktdaten oder auch Befragungsdaten gelöscht werden sollten und welche automatisierten sowie manuellen Verfahren dabei Anwendung finden. Die Herausforderungen, Datenintegrität und Anonymität gleichzeitig zu gewährleisten, wurden intensiv beleuchtet. Die Diskussion lieferte praxisnahe Ansätze für den Umgang mit Löschanfragen.
In der Session „(optisches) Fragebogendesign“ stand die Verbesserung der visuellen Benutzerführung in Online-Umfragen im Fokus. Die Teilnehmenden präsentierten Ideen wie Fortschrittsbalken, farbliche Elemente und thematische Zwischenseiten zur Auflockerung langer Fragebögen. Es wurde diskutiert, wie ein konsistentes Design auf verschiedenen Endgeräten umgesetzt werden kann. Ziel war es, die Orientierung der Befragten zu erleichtern und Ermüdungserscheinungen zu verringern.
Die Session „Preload CTRL“ präsentierte ein Konzept zur gleichzeitigen Verwaltung mehrerer Stichproben im Feld. Es ging um die Möglichkeit, verschiedene Sample-Teile parallel zu steuern und dynamisch zu aktualisieren. Ansätze zur zeitnahen Integration von Korrekturen und Anpassungen wurden erörtert. Obwohl konkrete Lösungen noch in Arbeit sind, zeigte die Diskussion großes Interesse an flexibleren Feldmanagement-Tools.
In der Session „Vergleichbarkeit über Datensätze, Kohorten, Länder hinweg“ wurde die Herausforderung der Harmonisierung unterschiedlicher Datensätze thematisiert. Die Diskussion drehte sich um Ansätze zur Standardisierung von Variablen und Messinstrumenten über Studien und Ländergrenzen hinweg. Einheitliche Standards wurden als Schlüsselfaktor für valide länderübergreifende Analysen hervorgehoben. Die Teilnehmenden beleuchteten sowohl methodische als auch praktische Umsetzungsfragen.
Die Session „Feldmonitoring/ Best Practice Qualitätsmonitoring“ widmete sich der kontinuierlichen Überwachung des Erhebungsprozesses. Es wurden verschiedene Kennzahlen und Dashboard-Tools vorgestellt, die eine frühzeitige Intervention ermöglichen sollen. Die Diskussion zeigte, wie durch regelmäßiges Monitoring die Interviewqualität verbessert werden kann. Ziel war es, präventiv gegen Fehlentwicklungen im Feld vorzugehen.
In der Session „Zufriedenheit Fragesteller:innen“ stand die Motivation derjenigen im Vordergrund, die Umfragefragen einreichen. Es wurde betont, dass die Vorteile von Panelstudien stärker kommuniziert werden sollten, um Fragesteller:innen langfristig zu binden. Ansätze zur Erweiterung des Dienstleistungsangebots wurden diskutiert. Die Teilnehmenden unterstrichen, dass ein intensiver Austausch zwischen Fragestellern und Panelbetreibern essenziell ist.
Die Session „Software für Online Umfragen / Outsourcing vs. mehr in house“ beleuchtete die Vor- und Nachteile von externen Softwarelösungen im Vergleich zu internen Entwicklungen. Es wurde erörtert, wie Abhängigkeiten von Lizenzgebern reduziert und interne Kompetenzen gestärkt werden können. Erfolgreiche Beispiele mit Open-Source-Software wurden als mögliche Alternative vorgestellt. Die Diskussion zeigte, dass eine hybride Strategie je nach den vorhandenen Ressourcen sinnvoll sein kann.
In der Session „Methodenswitch CATI/CAPI → CAWI“ wurden die Herausforderungen des Übergangs von klassischen Interviewmethoden zu webbasierten Umfragen diskutiert. Die Teilnehmenden beleuchteten notwendige Anpassungen im Fragebogen, um eine reibungslose Umstellung zu gewährleisten. Dabei wurden Themen wie Kontaktstrategien und der Umgang mit erhöhten Missings aufgegriffen. Das Ziel war ein fließender Methodenwechsel, der den Ansprüchen aller Beteiligten gerecht wird.
Die Session „Deep Learning“ untersuchte das Potenzial moderner Algorithmen zur automatischen Kodierung offener Antworten und unstrukturierter Daten. Es wurden Ansätze wie Audiotranskription und Sentiment-Analysen vorgestellt, die neue Einblicke in die Datenauswertung ermöglichen können. Praktische Erfahrungen wurden ausgetauscht und Herausforderungen bei der Implementierung diskutiert. Die Diskussion machte deutlich, dass Deep Learning innovative Möglichkeiten in der Datenaufbereitung eröffnet.
In der Session „Datenqualitätsprüfung“ wurde die Implementierung verschiedener Prüfverfahren zur Sicherung der Datenqualität erörtert. Es ging um Filterchecks, Rangechecks und den Umgang mit Inkonsistenzen sowohl innerhalb als auch zwischen Befragungswellen. Die Teilnehmenden diskutierten, wie fehlerhafte Angaben markiert und – wenn möglich – korrigiert werden können. Dabei wurde betont, dass eine transparente Bereitstellung von Original- und bereinigten Daten essenziell ist.
Die Session „Steuerungskreis für Surveys“ schloss den Workshop ab und beschäftigte sich mit der Einrichtung zentraler Koordinationsgremien. Es wurde diskutiert, wie durch Bündelung von Expertise standardisierte Prozesse und ein intensiver Wissensaustausch über verschiedene Surveys hinweg ermöglicht werden können. Die Idee einer zentralen Beratungseinheit zur Unterstützung von Studien wurde dabei als zukunftsweisend erachtet. Der interdisziplinäre Austausch in einem solchen Gremium wurde als entscheidend für die langfristige Effizienzsteigerung hervorgehoben.
ChatGPT hat den Kurzbericht über die Sessions auf Grundlage eines kollaborativen Protokolls erzeugt, das zum Teil viel reichhaltiger ist und auch Hinweise auf weiterführendes Material enthält.
SLOW 2025 vom 03. bis 05. Februar 2025 in Mannheim
Der nächste Survey-Lifecycle-Operators-Workshop (SLOW) findet vom 03. bis 05. Februar 2025 an der Universität Mannheim statt.
Alle Interessenten sind herzlich eingeladen. Die Anmeldung ist ab jetzt geöffnet.
Das Prinzip des „Survey Lifecycle Operators Workshop“ (SLOW) ist das altbewährte: ein Szene-Treffen von Menschen im Maschinenraum der deutschsprachigen Surveyforschung, egal ob Fragebogenentwicklung, Sampling, Feldsteuerung, Survey-Methoden, Datenaufbereitung, Nutzerbetreuung, Projektbeantragung oder -ausschreibung, etc. pp.: Alle sind willkommen! Das Format ist Open Space, also eine Konferenz aus strukturierten „Kaffeepausen“, die sich über die letzten mehr als 10 Jahre als sehr fruchtbar erwiesen hat.
Die Anmeldung zum Workshop ist bis zum 17. Januar 2025 möglich. Weitere Informationen zum Workshop und zur Anmeldung findet ihr hier:
Mitarbeiter*in beim SHARE-FDZ gesucht
Liebe Survey Data Community,
hier eine interessante Stellenausschreibung beim SHARE-FDZ:
https://share-eric.eu/news-events/job-offers/job-offer-sbi-research-associate-f/m/d