
The 14th German Stata Users Group meeting is announced to be held Friday, June 10, 2016 at GESIS in Cologne. Deadline for submissions is March 1, 2016.
The 14th German Stata Users Group meeting is announced to be held Friday, June 10, 2016 at GESIS in Cologne. Deadline for submissions is March 1, 2016.

Die 8. Konferenz der europäischen DDI-Nutzer_innen findet am 6. und 7. Dezember in Köln statt und bietet den deutschsprachigen Interessierten die Möglichkeit, auf kurzem Weg Zugang zur community zu bekommen. Die Konferenzwebseite enthält schon jetzt einige Hinweise.

In Forschungsdatenzentren wird oft programmiert. Wer programmiert, entwickelt Software. Joel Spolsky definiert in einem älteren und trotzdem lesenswerten Beitrag ein Mindestmaß an Wissen über Zeichensätze und -kodierung: The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
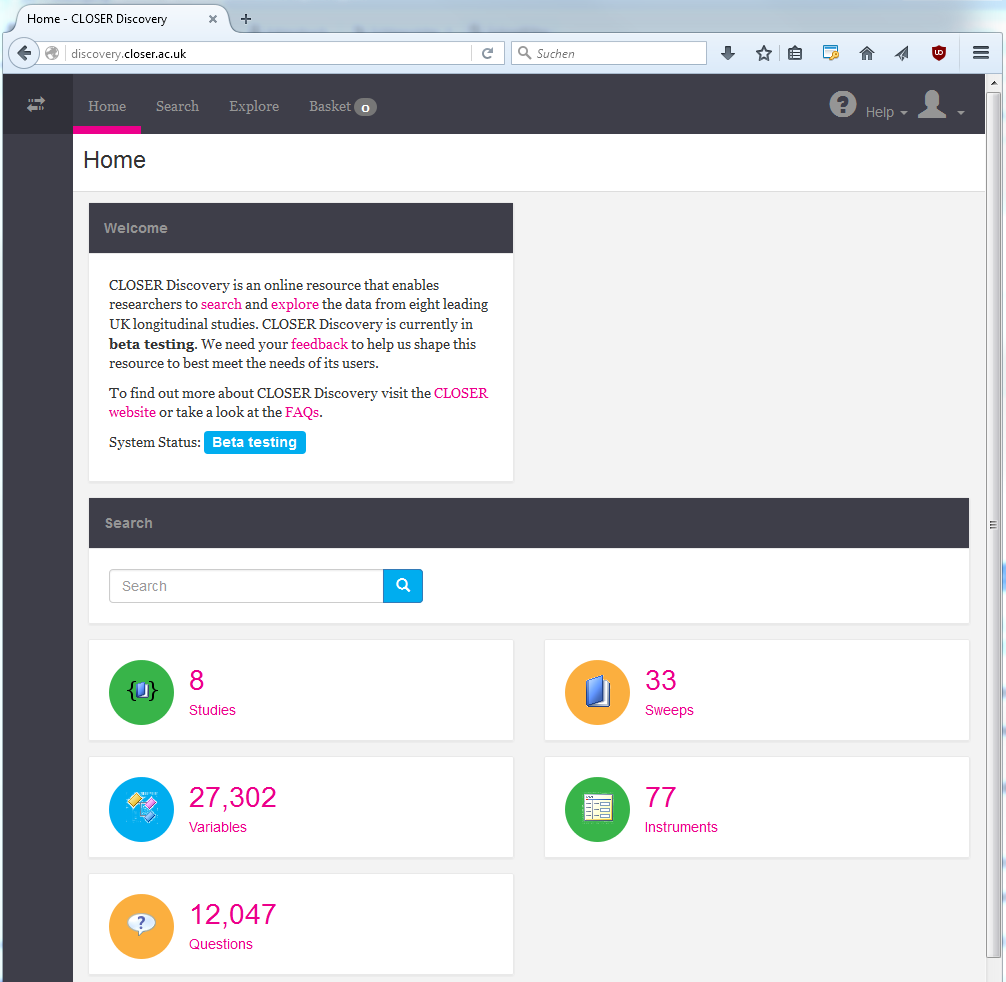 Acht UK-Längsschnittstudien werden über das neue Portal CLOSER Discovery erschlossen. In einem einstündigen Webinar am 25. Februar wird die Plattform vorgestellt. Die Anmeldung ist kostenlos.
Acht UK-Längsschnittstudien werden über das neue Portal CLOSER Discovery erschlossen. In einem einstündigen Webinar am 25. Februar wird die Plattform vorgestellt. Die Anmeldung ist kostenlos.
[via DDI-users]

Das SOEP richtet am 22./23. Februar 2016 den nächsten Workshop „Datenaufbereitung und Dokumentation“ in Berlin am DIW aus.
Wie im letzten Jahr findet der Workshop im Vorfeld des dann mittlerweile 10. Workshops der deutschsprachigen Panelsurveys statt, der direkt im Anschluss am 23. und 24. Februar 2016 geplant ist.
Die Anmeldung zu beiden Veranstaltungen ist ab sofort möglich.
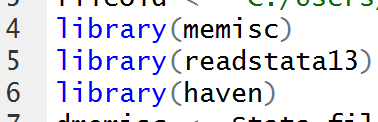
Lange Zeit hat das Paket foreign gute Dienste geleistet beim Öffnen und Schreiben von Stata-Datendateien (mit der Dateiendung dta). Die Entwicklung dieser Funktion des Pakets wird leider mit Stata Version 12 eingefroren. Dateien von Stata 13 werden nicht mehr unterstützt.
Die Hilfe zu foreign (s. S. 6 in der Dokumentation) nennt die Pakete memisc und readstata13 als Alternativen. Etwas Recherche fördert dann noch haven zu Tage.
Es folgen die Ergebnisse eines kleinen Tests, bei dem ein etwas erweiterter (construct_test_data.do) auto-Datensatz, wie er von Stata 13 gespeichert wird, Verwendung fand. Hier wurden zweisprachige Label, Umlaute und weitere Missings eingebaut.
Testsieger ist readstata13 von Jan Marvin Garbuszus, Sebastian Jeworutzki u.a. Im von read.dta13 importierten Objekt sind die Label-Informationen aus dem Datensatz als Attribute auch zweisprachig vorhanden.
An zweiter Stelle kommt haven von Hadley Wickham, der die ReadStat C library von Evan Miller verwendet, was prinzipiell nach einer guten Idee klingt. Die Version 0.2.0.9000 importiert zwar etwas, RStudio verweigert aber die Ansicht mit view. Im importierten Objekt ist die Mehrsprachigkeit in den Labels leider dahin.
Das Paket memisc von Martin Elff scheitert vollständig. In Version 0.97 bricht Stata.file den Import ab.
(Danke an Guido Schulz für den Hinweis zu readstata13.)

This session invites presentations dealing with structured metadata in a standardized form across the survey life-cycle: models, systems and tools for i.e. instrument design, data entry, data processing, maintaining data documentation, and capturing and storing the metadata within a repository for later reuse. There is increased interest in supporting the comparison and harmonization of studies/waves over space and time, and across studies, especially at the level of theoretical concepts, questions, and variables to which structured metadata is well suited.
Capturing metadata as early on in the survey life-cycle as possible in a structured way enhances transparency and quality, enables reproducible research and reuse of survey components for other waves or surveys.
A wide range of different products and services for different users can be generated on the basis of computer-processable metadata like web-based information systems, traditional codebooks, command setups for statistical packages, question banks, and searching and locating of data which assist in the use or interpretation of the data.
Papers are invited on, but not limited to, the following topics: reuse of metadata across space, time, and studies, metadata banks such as for questions and classifications, metadata-driven processes, and metadata-driven information systems, possibly using the major specification for social science metadata, DDI Lifecycle (DDI 3 branch of the Data Documentation Initiative).
The session is aimed at survey designers and implementers, data and metadata managers, information system managers of cross-national surveys, metadata experts, and others.
Session at the 9th International Conference on Social Science Methodology Research Committee on Logic and Methodology RC33
Conference dates: 11-16 September 2016
Venue: University of Leicester, UK
Deadline: 21 January 2016

This session invites presentations dealing with structured metadata in a standardized form across the data life-cycle: case studies, systems and tools for i.e. instrument design, data entry, data processing, maintaining data documentation, and capturing and storing the metadata within a repository for later re-use. Capturing metadata as early on in the survey life-cycle as possible in a structured way enhances transparency and quality, supports harmonization and comparison of studies, and enables reproducible research and reuse of survey components for other waves or surveys. Metadata management can be seen as an integrated part of the survey research process. A wide range of different products and services for different audiences can be generated on the basis of metadata like web-based information systems, traditional codebooks, command setups for statistical packages, question banks, and searching and locating of data. Papers are invited on, but not limited to, the following topics: reuse of metadata across space, time, and studies, metadata banks such as for questions and classifications, and metadata-driven information systems, possibly using DDI Lifecycle (Data Documentation Initiative). The session is aimed at survey designers and implementers, data and metadata managers, information system managers of cross-national surveys, metadata experts, and others.
Session at the 5th Biennial ACSPRI Social Science Methodology Conference 2016
ACSPRI – Australian Consortium for Social and Political Research Incorporated
Theme: Social science in Australia: 40 years on
Conference dates: Tuesday July 19 – Friday July 22, 2016
Venue: The University of Sydney, Sydney, Australia
Deadline: Friday March 4, 2016
 Die Einreichungsfrist für Beiträge zur European DDI User Conference endet am 6. September 2015. Die Konferenz selbst findet am 2./3. Dezember in Kopenhagen statt. Die Konferenzwebseite enthält schon jetzt die wichtigsten Hinweise und den CfP.
Die Einreichungsfrist für Beiträge zur European DDI User Conference endet am 6. September 2015. Die Konferenz selbst findet am 2./3. Dezember in Kopenhagen statt. Die Konferenzwebseite enthält schon jetzt die wichtigsten Hinweise und den CfP.

The Consortia Advancing Standards in Research Administration Information (CASRAI) provides a dictionary containing terms for the Research Data Domains. Each term has a unique identifier (UUID) and a URL that can be used as references to enhance reading comprehension of documents by hyperlinking terms to their definition. The URL for each term contains a link to a Discussion page to complete the feedback loop with the community of users.
The Glossary has been developed in consultation with vocabulary experts and practitioners from a wide cross-section of stakeholder groups. It is meant to be a practical reference for individuals and working groups concerned with the improvement of research data management, and as a meeting place for further discussion and development of terms. The aim is to create a stable and sustainably governed glossary of community accepted terms and definitions, and to keep it relevant by maintaining it as a ‘living document’ that is updated when necessary.
Form other sections of the dictionary one can return to this pilot section using the top-menu item Filter by and selecting Research Data Domain. To see all terms in the CASRAI dictionary (including the RDC terms), go here: http://dictionary.casrai.org/Category:Terms
In addition to direct comments on specific terms in the Glossary CASRAI is very interested in receiving feedback about the Glossary in general. Here is a short survey: https://www.surveymonkey.com/r/Glossary_ResearchDataManagement
This section of the dictionary is developed and maintained by Research Data Canada’s (RDC) Standards & Interoperability Committee (http://www.rdc-drc.ca) in collaboration with CASRAI. It is made publicly available under a Creative Commons Attribution Only license (CC-BY).
(via [DDI-users])