
Am 19. und 20. Februar hat der der Workshop “Datenaufbereitung und Dokumentation” in diesem Jahr am Leibniz-Institut für Bildungsverläufe in Bamberg stattgefunden. In insgesamt 15 Sessions wurden Themen diskutiert, die uns als Datenproduzenten aktuell beschäftigen. Wie immer wurde dabei ein breites Spektrum abgedeckt, von prozessbegleitender Dokumentation über Datenedition bis zu Datenschutz, Nutzersupport und Projektmanagement. Es gab vorab keine fixe Agenda, sondern die Themen haben sich nach dem OpenSpace-Ansatz aus dem Kreis der Teilnehmerinnen und Teilnehmer ergeben.
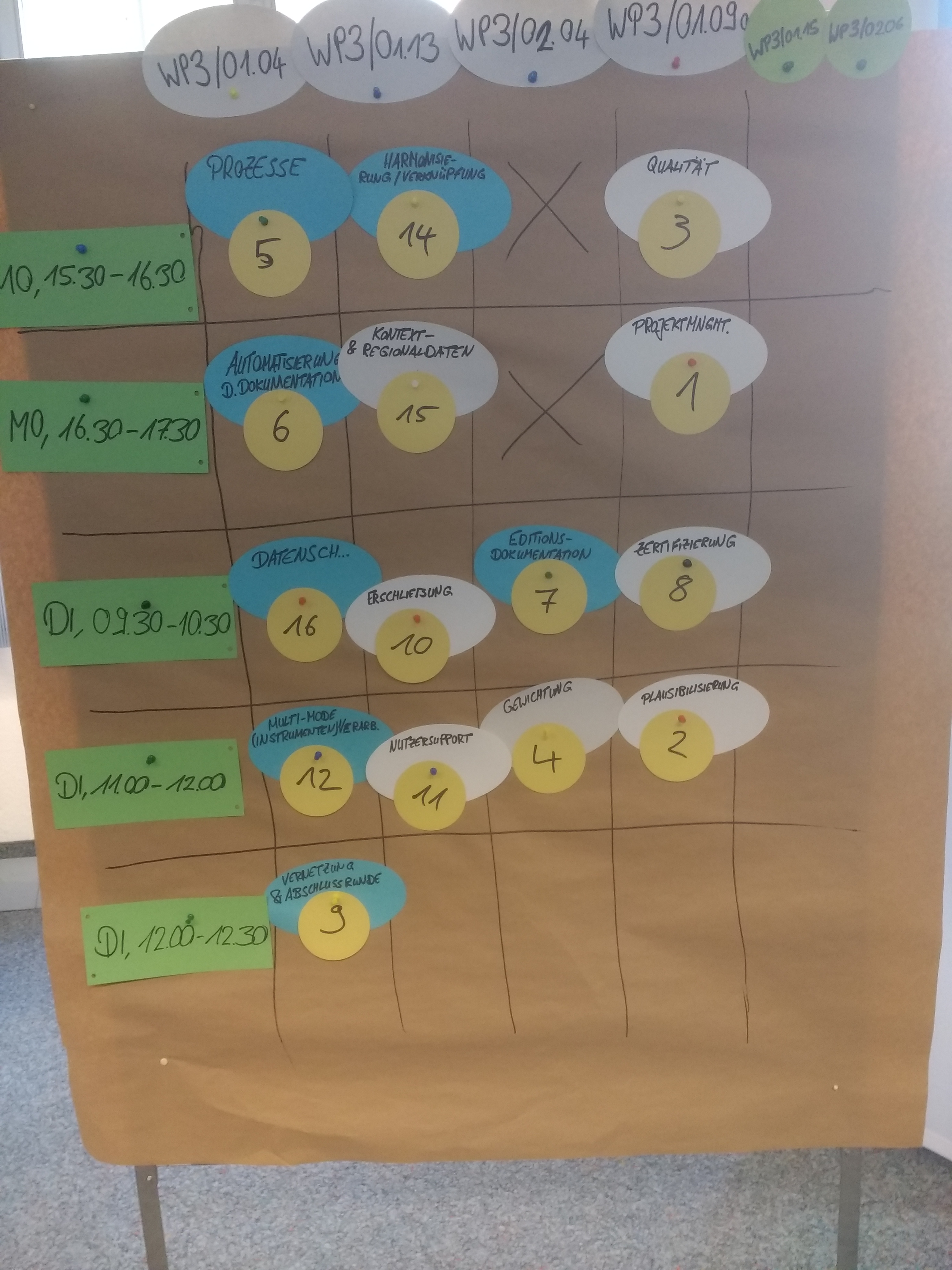 Der Teilnehmerkreis ist wieder gewachsen und neben vielen alten Bekannten konnten wir auch in diesem Jahr wieder neue Kolleginnen und Kollegen begrüßen. Noch einmal herzlichen Dank an die hervorragenden Gastgeberinnen und Gastgeber vom FDZ des NEPS, die trotz kurzfristiger räumlicher und gesundheitlicher Schwierigkeiten einen sehr produktiven und kurzweiligen Workshop ermöglicht haben! Für das nächste Jahr hat sich das FDZ des DZHW dankenswerter Weise bereiterklärt uns zu beherbergen.
Der Teilnehmerkreis ist wieder gewachsen und neben vielen alten Bekannten konnten wir auch in diesem Jahr wieder neue Kolleginnen und Kollegen begrüßen. Noch einmal herzlichen Dank an die hervorragenden Gastgeberinnen und Gastgeber vom FDZ des NEPS, die trotz kurzfristiger räumlicher und gesundheitlicher Schwierigkeiten einen sehr produktiven und kurzweiligen Workshop ermöglicht haben! Für das nächste Jahr hat sich das FDZ des DZHW dankenswerter Weise bereiterklärt uns zu beherbergen.
Vielen Dank auch an alle Teilnehmerinnen und Teilnehmer und bis zum nächsten Jahr in Hannover!



 In der jüngsten Ausgabe der Zeitschrift „
In der jüngsten Ausgabe der Zeitschrift „