
Eine Tradition in den letzten Zügen? Anlässlich einer aktuellen Stellungnahme der American Statistical Association gibt es von der Royal Statistical Society einen Hintergundbericht mit vielen Links.
Eine Tradition in den letzten Zügen? Anlässlich einer aktuellen Stellungnahme der American Statistical Association gibt es von der Royal Statistical Society einen Hintergundbericht mit vielen Links.

Schon wieder ein Webinar aus UK. Am 22. März geht es um die Längsschnittdaten des UK Data Service. Gibt es E-Learning-Angebote im deutschsprachigen Raum, die in die Angebote der Forschungsdatenzentren einführen?
Wo können Beiträge zu Themen der operativen Arbeit in Forschungsdatenzentren publiziert werden? Eine Liste, die derzeit noch einen Schwerpunkt im Bereich Metadaten/DDI hat, findet sich auf BibSonomy.org. Daraus könnte mittelfristig auch eine Bibliographie entstehen. Weitere Hinweise können gerne in den Kommentaren gegeben werden.
[Der Beitrag wurde motiviert duch Diskussionen auf dieser Veranstaltung.]

The 14th German Stata Users Group meeting is announced to be held Friday, June 10, 2016 at GESIS in Cologne. Deadline for submissions is March 1, 2016.

Die 8. Konferenz der europäischen DDI-Nutzer_innen findet am 6. und 7. Dezember in Köln statt und bietet den deutschsprachigen Interessierten die Möglichkeit, auf kurzem Weg Zugang zur community zu bekommen. Die Konferenzwebseite enthält schon jetzt einige Hinweise.

In Forschungsdatenzentren wird oft programmiert. Wer programmiert, entwickelt Software. Joel Spolsky definiert in einem älteren und trotzdem lesenswerten Beitrag ein Mindestmaß an Wissen über Zeichensätze und -kodierung: The Absolute Minimum Every Software Developer Absolutely, Positively Must Know About Unicode and Character Sets (No Excuses!)
 Acht UK-Längsschnittstudien werden über das neue Portal CLOSER Discovery erschlossen. In einem einstündigen Webinar am 25. Februar wird die Plattform vorgestellt. Die Anmeldung ist kostenlos.
Acht UK-Längsschnittstudien werden über das neue Portal CLOSER Discovery erschlossen. In einem einstündigen Webinar am 25. Februar wird die Plattform vorgestellt. Die Anmeldung ist kostenlos.
[via DDI-users]

Das SOEP richtet am 22./23. Februar 2016 den nächsten Workshop „Datenaufbereitung und Dokumentation“ in Berlin am DIW aus.
Wie im letzten Jahr findet der Workshop im Vorfeld des dann mittlerweile 10. Workshops der deutschsprachigen Panelsurveys statt, der direkt im Anschluss am 23. und 24. Februar 2016 geplant ist.
Die Anmeldung zu beiden Veranstaltungen ist ab sofort möglich.
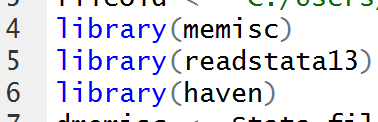
Lange Zeit hat das Paket foreign gute Dienste geleistet beim Öffnen und Schreiben von Stata-Datendateien (mit der Dateiendung dta). Die Entwicklung dieser Funktion des Pakets wird leider mit Stata Version 12 eingefroren. Dateien von Stata 13 werden nicht mehr unterstützt.
Die Hilfe zu foreign (s. S. 6 in der Dokumentation) nennt die Pakete memisc und readstata13 als Alternativen. Etwas Recherche fördert dann noch haven zu Tage.
Es folgen die Ergebnisse eines kleinen Tests, bei dem ein etwas erweiterter (construct_test_data.do) auto-Datensatz, wie er von Stata 13 gespeichert wird, Verwendung fand. Hier wurden zweisprachige Label, Umlaute und weitere Missings eingebaut.
Testsieger ist readstata13 von Jan Marvin Garbuszus, Sebastian Jeworutzki u.a. Im von read.dta13 importierten Objekt sind die Label-Informationen aus dem Datensatz als Attribute auch zweisprachig vorhanden.
An zweiter Stelle kommt haven von Hadley Wickham, der die ReadStat C library von Evan Miller verwendet, was prinzipiell nach einer guten Idee klingt. Die Version 0.2.0.9000 importiert zwar etwas, RStudio verweigert aber die Ansicht mit view. Im importierten Objekt ist die Mehrsprachigkeit in den Labels leider dahin.
Das Paket memisc von Martin Elff scheitert vollständig. In Version 0.97 bricht Stata.file den Import ab.
(Danke an Guido Schulz für den Hinweis zu readstata13.)

This session invites presentations dealing with structured metadata in a standardized form across the survey life-cycle: models, systems and tools for i.e. instrument design, data entry, data processing, maintaining data documentation, and capturing and storing the metadata within a repository for later reuse. There is increased interest in supporting the comparison and harmonization of studies/waves over space and time, and across studies, especially at the level of theoretical concepts, questions, and variables to which structured metadata is well suited.
Capturing metadata as early on in the survey life-cycle as possible in a structured way enhances transparency and quality, enables reproducible research and reuse of survey components for other waves or surveys.
A wide range of different products and services for different users can be generated on the basis of computer-processable metadata like web-based information systems, traditional codebooks, command setups for statistical packages, question banks, and searching and locating of data which assist in the use or interpretation of the data.
Papers are invited on, but not limited to, the following topics: reuse of metadata across space, time, and studies, metadata banks such as for questions and classifications, metadata-driven processes, and metadata-driven information systems, possibly using the major specification for social science metadata, DDI Lifecycle (DDI 3 branch of the Data Documentation Initiative).
The session is aimed at survey designers and implementers, data and metadata managers, information system managers of cross-national surveys, metadata experts, and others.
Session at the 9th International Conference on Social Science Methodology Research Committee on Logic and Methodology RC33
Conference dates: 11-16 September 2016
Venue: University of Leicester, UK
Deadline: 21 January 2016