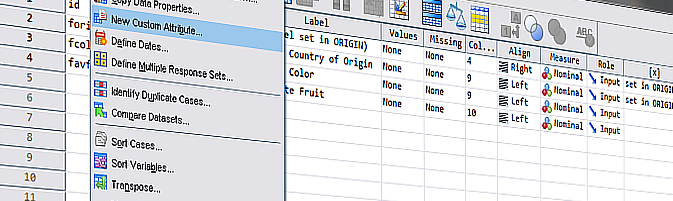
Adding custom variable-attributes is a useful feature of SPSS available since version 14 of 2005. It can be used to assign additional information to variables and store it with the survey data, e.g. metadata or paradata. However, compared to the attributes reserved by SPSS (like variable labels or value labels), user-defined attributes demand extra attention and there are some pitfalls to look out for. When datasets are combined using MATCH FILES or ADD FILES, attributes or their values may easily and unintentionally be dropped in the process. This post aims to demonstrate, how custom attributes are handled by SPSS (version 22) when applying a MATCH FILES command, in order to raise attention about the issue. (The ADD FILES command leads to similar results and is therefore not demonstrated here.) In conclusion, a solution is presented how associated problems can be avoided in the first place.
Some data for demo
The following code creates the datasets named FRUIT, COLOR and ORIGIN with two variables and three cases each. The casewise data is merely necessary for matching the datasets and the emphasis is on the additionally defined variable attributes.
Dataset FRUIT: No custom attributes
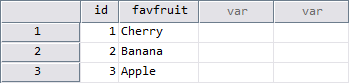
NEW FILE. DATA LIST /id 1-2 favfruit 3-9(A). BEGIN DATA 1 Cherry 2 Banana 3 Apple END DATA. VARIABLE LABELS id "ID (label set in FRUIT)" /favfruit "Favourite Fruit". DATASET NAME FRUIT.
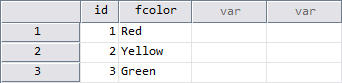
Dataset COLOR: One custom attribute [z]

NEW FILE.
DATA LIST /id 1-2 fcolor 3-9(A).
BEGIN DATA
1 Red
2 Yellow
3 Green
END DATA.
VARIABLE LABELS id "ID (label set in COLOR)"
/fcolor "Fruit's Color".
VARIABLE ATTRIBUTE
VARIABLES = id
ATTRIBUTE = z("set in COLOR")
/VARIABLES = fcolor
ATTRIBUTE = z("set in COLOR").
DATASET NAME COLOR.
Dataset ORIGIN: Three custom attributes [x], [y] and [z]
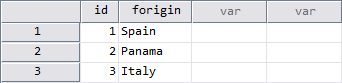

NEW FILE.
DATA LIST /id 1-2 forigin 3-9(A).
BEGIN DATA
1 Spain
2 Panama
3 Italy
END DATA.
VARIABLE LABELS id "ID (label set in ORIGIN)"
/forigin "Fruit's Country of Origin".
VARIABLE ATTRIBUTE
VARIABLES = id
ATTRIBUTE = x("set in ORIGIN") y("set in ORIGIN") z("set in ORIGIN")
/VARIABLES = forigin
ATTRIBUTE = x("set in ORIGIN") y("set in ORIGIN") z("set in ORIGIN").
DATASET NAME ORIGIN.
Blending the data
Please note that customization [z] is defined in COLOR as well as in ORIGIN and the reoccurring variable “id” has different attribute-values in each dataset. Which attributes and values will end up in the combined dataset after a MATCH FILES command has been applied?
MATCH FILES #1: Missing attribute-definitions and -values
The sequence of files in the following syntax is essential:
NEW FILE. MATCH FILES FILE = FRUIT /FILE = COLOR /FILE = ORIGIN /BY id. EXECUTE. DATASET NAME MATCHEDFILES1.
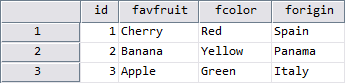
This syntax results in a 3×4 data matrix which contains all the cases’ data from FRUIT, COLOR and ORIGIN in a corresponding variable order.
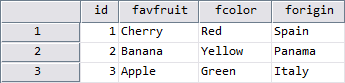

However, the Variable View reveals some effects, which might be considered counter-intuitive and surprising:
- user-attributes [x] and [y] were not transferred, although the associated data (ORIGIN) was matched successfully
- variable “id” contains no value for [z] although there were customizations for this attribute in two of the included files (COLOR and ORIGIN)
- on the other hand, the value of [z] was entered for variable “forigin”
- the variable label for “id” was not applied from the last matched file (ORIGIN) but according to the first file in the matching sequence (FRUIT)
MATCH FILES #2: Missing attribute-values
Slightly changing the MATCH FILES command will lead to a different result. For the next example, only ORIGIN and COLOR were swapped in the sequence of files:
NEW FILE. MATCH FILES FILE = FRUIT /FILE = ORIGIN /FILE = COLOR /BY id. EXECUTE. DATASET NAME MATCHEDFILES2.
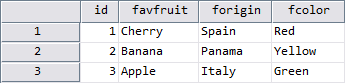

Again, the result is a 3×4 data matrix. This time, however, …
- … the custom attributes [x], [y] and [z] are included,
- but all attribute-values are still missing for variable “id”
MATCH FILES #3: Complete attribute-definitions and -values
In the final attempt, the sequence of matched files starts with the dataset, that contains attribute-definitions and -values for all of attributes being used in the demo-datasets.
NEW FILE. MATCH FILES FILE = ORIGIN /FILE = COLOR /FILE = FRUIT /BY id. EXECUTE. DATASET NAME MATCHEDFILES3.
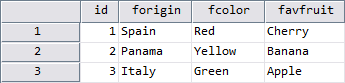

Summary
When combining datasets with different custom attributes in SPSS, the sequence of commands also determines how the variable properties will be integrated. MATCH FILES will not add further attributes after a file was processed, which already contained a compilation of custom attributes. However, SPSS will fill in the attribute-values if the same attributes exist in various files and no existing value needs to be replaced. In other words: If a variable exists in multiple source files, the attribute-definitions and -values of the first file in the MATCH FILES queue will be transferred.
Thus, it sometimes may be worth considering to include an extra file in the matching sequence, which exclusively contains all the attribute-information and can processed by MATCH FILES primarily:
NEW FILE.
DATA LIST /id 1-2 favfruit 3-9(A) fcolor 3-9(A) forigin 3-9(A).
VARIABLE LABELS id "set in METADATA"
/favfruit "set in METADATA"
/fcolor "set in METADATA"
/forigin "set in METADATA".
VARIABLE ATTRIBUTE
VARIABLES = id
ATTRIBUTE = x("set in METADATA") y("set in METADATA") z("set in METADATA")
/VARIABLES = favfruit
ATTRIBUTE = x("set in METADATA") y("set in METADATA") z("set in METADATA")
/VARIABLES = fcolor
ATTRIBUTE = x("set in METADATA") y("set in METADATA") z("set in METADATA")
/VARIABLES = forigin
ATTRIBUTE = x("set in METADATA") y("set in METADATA") z("set in METADATA").
DATASET NAME METADATA.
NEW FILE.
MATCH FILES FILE = METADATA
/FILE = FRUIT
/FILE = COLOR
/FILE = ORIGIN
/BY id.
EXECUTE.
DATASET NAME MATCHEDFILES4.

Downloads
| example.sps |